
#06 - 06/2016
- 01001100110106 – cyborg
- “free” as in “free software”: μικρό αφιέρωμα στο ελεύθερο λογισμικό:
- για την γέννηση της αλεπούς (Firefox)
- για τις σχέσεις ιδιοκτησίας
- για την κοινωνικότητα και την εμκετάλλευση της εργασίας
- για το κέρδος και την υπεραξία
- για τους προγραμματιστές (ή developers - το ίδιο κάνει)
- συγκεντροποίηση: υλικό, λογισμικό και data ως κεφάλαιο
- το τέταρτο παράδειγμα(;): η μηχανική διαμεσολάβηση της επιστημονικής σκέψης
- νανοτεχνολογίες: μερικά γνωστά άγνωστα...
- The Matrix: ψηφιακοί μεσσίες και η μεταφυσική του βιοπληροφορικού παραδείγματος
- η ματωμένη υλικότητα του “άυλου” καπιταλισμού
- ιστορία επιστημονικού μυστικισμού: τάο και φυσική
- bytes & genes
το τέταρτο παράδειγμα(;): η μηχανική διαμεσολάβηση της επιστημονικής σκέψης
Ο όρος “Παράδειγμα”, μαζί με τον συνοδευτικό του “Αλλαγή Παραδείγματος”, από τότε που πρωτοεμφανίστηκαν στο κλασσικό πλέον βιβλίο του Τόμας Κουν για τη δομή των επιστημονικών επαναστάσεων, έχουν υποστεί όχι μόνο την αναμενόμενη κριτική, αλλά και μια κατάχρηση που κινδυνεύει να τους καταστήσει άχρηστους ως εργαλεία κατανόησης της επιστημονικής πρακτικής. [1Για ένα πιο χειροπιαστό παράδειγμα κακοποίησης εννοιών, μπορεί κανείς να δει το τι έχει τραβήξει η λέξη “επανάσταση” στα χέρια των διαφημιστών. Για να μην μιλήσουμε για τους “πολιτικούς ειδικούς” του είδους, που στα μέρη μας τους συναντάει κανείς σε κάθε γωνία.] Από κει που κάποτε θεωρούνταν απειλητικοί για το επιστημονικό status quo ή, για να είμαστε κάπως πιο μετριοπαθείς στις εκφράσεις μας, τουλάχιστον υπονομευτικοί για τον τρόπο που οι επιστήμονες κατανοούσαν τον εαυτό τους και νομιμοποιούσαν προς τα έξω τη δραστηριότητά τους ως αναζήτηση της Αλήθειας, τώρα πλέον δεν είναι καθόλου σπάνιο να τους χρησιμοποιούν οι ίδιοι οι επιστήμονες ως διαφημιστικό σλόγκαν για καινούριες ανακαλύψεις, είτε θεωρητικές είτε τεχνολογικές. Παρ' όλα αυτά, πρόκειται για όρους που διατηρούν μιαν αξία, αν τουλάχιστον γνωρίζει κανείς για τι πράγμα μιλάει. Σε μια κίνηση παρόμοια με εκείνη της κοινωνιολογίας στα πρώτα της βήματα, που έθεσε στο επίκεντρό της τη θρησκεία, αναλύοντάς την ως προς τα κοινωνικά της συμφραζόμενα (από τον Μαρξ μέχρι τον Ντυρκέμ και τον Βέμπερ), η κοινωνιολογία της επιστήμης, από τον Κουν και μετά άφησε ως παρακαταθήκη το εξής αυτονόητο(;) πλέον: καμμία επιστημονική αλλαγή μεγάλης κλίμακας δεν μπορεί να γίνει κατανοητή ως κίνηση που λαμβάνει χώρα αυστηρά στο εσωτερικό μιας επιστήμης. Κι αν η μάχη για τις επιστημονικές έννοιες υπερβαίνει τα όρια ενός στενά εννοούμενου ορθολογισμού και η έκβασή της καθορίζεται κι από παράγοντες εξω-επιστημονικούς - δηλαδή ιδεολογικούς, κοινωνικούς ή ακόμα και πολιτικούς - τότε η αντίληψη για μια καθαρή επιστήμη, “αμόλυντη από τα ταπεινά εγκόσμια”, που θα λειτουργεί ως προπύργιο της αντικειμενικής γνώσης, γίνεται στην καλύτερη περίπτωση μια χίμαιρα και στην χειρότερη απλό ιδεολόγημα. [2Το έργο του Κουν θεωρείται ορόσημο κυρίως στον αγγλοσαξωνικό κόσμο. Η ηπειρωτική Ευρώπη (κυρίως η Γαλλία) είχε να επιδείξει παρόμοιο έργο (αν και λιγότερο γνωστό, για προφανείς λόγους) ήδη πριν τον Κουν. Βλ. το βιβλίο του Dominique Lecourt, Marxism and Epistemology: Bachelard, Canguilhem and Foucault.]
Μέσα από τις σελίδες του cyborg αναφερόμαστε συχνά σε αυτό που ονομάζουμε καπιταλιστική αλλαγή παραδείγματος, δηλαδή στην διαδικασία εκείνη ριζικής αναδιάρθρωσης του καπιταλισμού τις τελευταίες δεκαετίες, που μπορεί να έχει στην αιχμή της τις τεχνολογικές εξελίξεις κατά κύριο λόγο, αλλά που τελικά φτάνει να διαπερνά εγκάρσια ολόκληρο το κοινωνικό πεδίο, από τις διαπροσωπικές σχέσεις και το εκπαιδευτικό σύστημα μέχρι τις μορφές πολιτικής εκπροσώπησης. Τον όρο “αλλαγή παραδείγματος” τον έχουμε δανειστεί φυσικά από το πεδίο της επιστημολογίας και τον χρησιμοποιούμε για τους δικούς μας σκοπούς κι όχι ως ακριβή αναλογία με τις επιστημονικές αλλαγές παραδείγματος. [3Βλ. σχετικό άρθρο στο τεύχος 4 του Cyborg, Περί αλλαγής παραδείγματος.]
Το ερώτημα ωστόσο γεννάται αυτόματα. Από τη στιγμή που η αναδιάρθρωση της καπιταλιστικής μηχανής απλώνεται σε τόσα πεδία, είναι δυνατό να μένει απ' έξω η ίδια η επιστήμη; Κι εδώ προφανώς δεν εννοούμε την επιστήμη από την άποψη των όποιων τεχνολογικών εφαρμογών παράγει, αλλά τον ίδιο τον πυρήνα των θεωριών και των μεθοδολογιών της. Με άλλα λόγια, μπορεί να εντοπιστεί ένας κυρίαρχος τρόπος του επιστημονικού σκέπτεσθαι, δηλαδή ένα Παράδειγμα, εδώ και τώρα, στη σημερινή συγκυρία; Κι αν ναι, αυτό το Παράδειγμα είναι ένα ή μήπως κάθε επιστημονικός κλάδος έχει το δικό του; Η εύκολη απάντηση σε τέτοια ερωτήματα θα ήταν ότι αρκεί να κοιτάξουμε το τι παρήγαγαν οι τελευταίες επιστημονικές επαναστάσεις, στη βάση των οποίων δουλεύουν σήμερα οι επιστήμονες. Για παράδειγμα, θα μπορούσαμε να θεωρήσουμε ότι οι θεωρίες της σχετικότητας και η κβαντομηχανική αποτελούν δύο σταθερά θεμέλια της σύγχρονης φυσικής, παρέχοντας στους φυσικούς αντίστοιχες εννοιολογήσεις του χωροχρόνου και της αιτιότητας. Στον τομέα της βιολογίας τώρα, το κεντρικό δόγμα της, που θέλει το κύτταρο να είναι η βασική μονάδα της ζωής και το DNA ο φορέας όλων των απαραίτητων πληροφοριών, θα μπορούσε να θεωρηθεί ότι συνιστά ένα άλλο τέτοιο Παράδειγμα. Κι έτσι οι σημερινοί επιστήμονες που εκπαιδεύτηκαν κι εκπαιδεύονται να δουλεύουν στη βάση αυτών των Παραδειγμάτων μπορούν να κοιμούνται ήσυχοι. Καμμία απειλητική επανάσταση στον ορίζοντα.
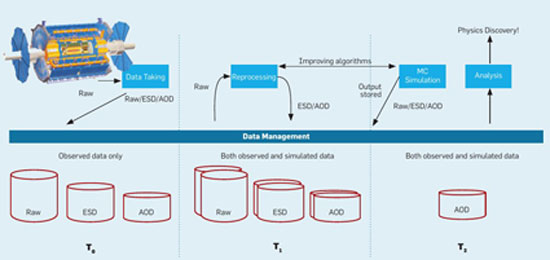
Σχεδιάγραμμα απεικόνισης των σταδίων επεξεργασίας των αρχικών δεδομένων από το πείραμα ATLAS στο CERN. Οι λεπτομέρειες δεν έχουν τόση σημασία εδώ. Ο αριθμός των σταδίων από μόνος του (μεταξύ των οποίων είναι και προσομοιώσεις για να καλιμπράρονται τα πρωτογενή δεδομένα) δείχνει πόσο μακριά είναι η αλυσίδα μέχρι να πάρουν τελικά τα δεδομένα τους οι φυσικοί για ανάλυση.
επιστήμη έντασης δεδομένων
Το 2008, στο γνωστό τεχνολαγνικό περιοδικό Wired, εμφανίστηκε ένα άρθρο με τον προβοκατόρικο τίτλο “Το τέλος της θεωρίας: ο κατακλυσμός δεδομένων καθιστά απαρχαιωμένη την επιστημονική μέθοδο”. Μεταφέρουμε εδώ ένα εκτεταμένο απόσπασμα:
Στην κλίμακα των petabyte, η πληροφορία δεν είναι πλέον ζήτημα ταξινόμησης και διάταξης σε τρεις ή τέσσερις διαστάσεις, αλλά ζήτημα στατιστικής, για την οποία θα είναι αδιάφορος ο αριθμός των διαστάσεων. Χρειάζεται μια τελείως διαφορετική προσέγγιση που θα είναι απαλλαγμένη από την απαίτηση της οπτικοποίησης των δεδομένων στην ολότητά τους. Μας αναγκάζει να δούμε τα δεδομένα καταρχήν μέσα από μια μαθηματική σκοπιά και μόνο σε δεύτερο χρόνο να βρούμε τα συμφραζόμενά τους. Για παράδειγμα, η Google δεν χρειάστηκε τίποτα άλλο παρά μόνο εφαρμοσμένα μαθηματικά για να κατακτήσει τον κόσμο της διαφήμισης. Ποτέ της δεν προσποιήθηκε ότι γνωρίζει το παραμικρό για την κουλτούρα και τις συμβάσεις της διαφήμισης – η μόνη της υπόθεση ήταν ότι θα κατάφερνε να βγει κερδισμένη διαθέτοντας απλώς καλύτερα δεδομένα και καλύτερα εργαλεία ανάλυσης. Και είχε δίκιο.
Η βασική φιλοσοφία της Google είναι ότι “δεν γνωρίζουμε γιατί μια συγκεκριμένη σελίδα είναι καλύτερη από μια άλλη”. Αν τα στατιστικά στοιχεία σε σχέση με τους εισερχόμενους συνδέσμους μάς λένε ότι όντως είναι καλύτερη, τότε αυτό μας αρκεί. Δεν χρειάζεται καμμία ανάλυση ως προς την σημασιολογία ή την αιτιολογία. Αυτός είναι ο λόγος που η Google μπορεί να μεταφράζει από γλώσσες που στην πραγματικότητα δεν «γνωρίζει» (αν της δοθεί η ίδια ποσότητα δεδομένων, η Google μπορεί με την ίδια ευκολία να μεταφράσει την γλώσσα των Klingon στα Φαρσί όπως και τα Γαλλικά στα Γερμανικά). Κι είναι επίσης ο λόγος που μπορεί να βρίσκει ποιες διαφημίσεις ταιριάζουν με ένα συγκεκριμένο περιεχόμενο χωρίς να γνωρίζει ή να υποθέτει το ο,τιδήποτε ούτε για τις διαφημίσεις ούτε για το περιεχόμενο.
...
Εδώ βρισκόμαστε μπροστά σ' έναν κόσμο όπου τα τεραστίων όγκων δεδομένα και τα εφαρμοσμένα μαθηματικά θα αντικαταστήσουν όλα τ' άλλα εργαλεία. Ξεχάστε όλες τις θεωρίες για την ανθρώπινη συμπεριφορά, από τη γλωσσολογία μέχρι την κοινωνιολογία. Ξεχάστε ταξινομικά σχήματα, οντολογίες και ψυχολογίες. Ποιος ξέρει γιατί οι άνθρωποι συμπεριφέρονται όπως συμπεριφέρονται; Το θέμα είναι ότι συμπεριφέρονται κι αυτή τη συμπεριφορά τους μπορούμε να την καταγράψουμε και να την μετρήσουμε με αδιανόητη μέχρι πρότινος πιστότητα. Αν έχουμε αρκετά δεδομένα, τότε τα νούμερα μιλάνε από μόνα τους.
Ωστόσο, στο στόχαστρο εδώ δεν βρίσκεται τόσο η διαφήμιση, αλλά η επιστήμη. Η επιστημονική μέθοδος βασίζεται στις ελέγξιμες υποθέσεις. Αυτά τα μοντέλα είναι στο μεγαλύτερο μέρος τους συστήματα, οπτικοποιημένα μέσα στο μυαλό των επιστημόνων. Κατόπιν τα μοντέλα ελέγχονται και τα πειράματα είναι που τελικά επιβεβαιώνουν ή διαψεύδουν τα θεωρητικά μοντέλα για το πώς λειτουργεί ο κόσμος. Αυτός είναι ο τρόπος της επιστήμης εδώ κι αιώνες.
Μέρος της εκπαίδευσης των επιστημόνων είναι να μαθαίνουν ότι η συσχέτιση δεν ταυτίζεται με την σχέση αιτιότητας κι ότι δεν μπορείς να εξάγεις συμπεράσματα απλά και μόνο βάσει του ότι το Χ συσχετίζεται με το Ψ (που θα μπορούσε να είναι κι απλή σύμπτωση). Πρέπει, αντιθέτως, να μπορείς να κατανοείς τους αφανείς μηχανισμούς που συνδέουν αυτά τα δύο. Από τη στιγμή που διαθέτεις ένα μοντέλο, τότε μπορείς να κάνεις με αξιοπιστία τη σύνδεση μεταξύ τους. Το να έχεις δεδομένα χωρίς κάποιο μοντέλο είναι σαν να έχεις σκέτο θόρυβο.
Με την εμφάνιση των δεδομένων μαζικής κλίμακας όμως, αυτή η προσέγγιση της επιστήμης - υπόθεση, μοντέλο, έλεγχος - γίνεται απαρχαιωμένη. Ας πάρουμε το παράδειγμα της φυσικής: τα νευτώνεια μοντέλα δεν ήταν τίποτα άλλο παρά χοντροκομμένες προσεγγίσεις της αλήθειας (λανθασμένα όταν εφαρμόζονται στο ατομικό επίπεδο, αλλά κατά τ' άλλα χρήσιμα). Πριν εκατό χρόνια, η κβαντομηχανική, βασισμένη στη στατιστική, μάς έδωσε μια καλύτερη εικόνα – όμως κι η κβαντομηχανική είναι απλώς ένα ακόμα μοντέλο, που ως τέτοιο, είναι κι αυτό ελαττωματικό· καρικατούρα μιας πραγματικότητας που είναι πολύ πιο σύνθετη. Ο λόγος που τις τελευταίες δεκαετίες η φυσική έχει διολισθήσει προς μια θεωρητική εικοτολογία περί εντυπωσιακών ν-διάστατων ενοποιημένων μοντέλων είναι το γεγονός ότι δεν γνωρίζουμε τον τρόπο για να τρέξουμε τα πειράματα εκείνα που θα διέψευδαν όλες αυτές τις υποθέσεις - απαιτούνται πολύ υψηλές ενέργειες, πολύ ακριβοί επιταχυντές, κ.τ.λ.
Η βιολογία οδεύει προς την ίδια κατεύθυνση. Τα μοντέλα που μάθαμε στο σχολείο σχετικά με “επικρατή” και “υπολειπόμενα” γονίδια που καθοδηγούν μια αυστηρά μεντελιανή διαδικασία αποδεικνύεται ότι τελικά είναι μια απλοποίηση της πραγματικότητας ακόμα πιο χοντροκομμένη από αυτή των νευτώνειων νόμων. Η ανακάλυψη των αλληλεπιδράσεων μεταξύ γονιδίων και πρωτεϊνών, όπως κι άλλων επιγενετικών παραγόντων, έχει κλονίσει την άποψη ότι το DNA συνιστά κάτι σαν πεπρωμένο και μάλιστα πλέον διαθέτουμε ενδείξεις ότι το περιβάλλον μπορεί να επηρεάζει χαρακτηριστικά που είναι κληρονομήσιμα, κάτι που εθεωρείτο γενετικά αδύνατο κάποτε.
...
Τώρα πλέον υπάρχει ένας καλύτερος τρόπος. Με τα petabyte μπορούμε να πούμε: “η συσχέτιση μας αρκεί”. Μπορούμε να σταματήσουμε να ψάχνουμε για μοντέλα. Μπορούμε να αναλύουμε τα δεδομένα χωρίς υποθέσεις περί του τι είναι πιθανό να βρούμε. Μπορούμε να ταΐζουμε τα υπολογιστικά cluster (τα μεγαλύτερα που έχουν υπάρξει ποτέ) με αριθμούς και να αφήνουμε τους στατιστικούς αλγορίθμους να βρίσκουν τα μοτίβα που δεν μπορεί να βρει η ίδια η επιστήμη.
Δεν θα αδικούσαμε όποιον επέλεγε να προσπεράσει άρθρα τέτοιας συμπυκνωμένης αλαζονείας με μια απλή συγκατάβαση. Το ζήτημα ωστόσο είναι ότι το εν λόγω άρθρο αποτέλεσε έκτοτε σημείο αναφοράς (ακόμα και με την αρνητική έννοια) για όσους προσπαθούν να κατανοήσουν τις μεταβολές που φέρνουν στο επιστημονικό πράττειν και σκέπτεσθαι οι τελευταίες πληροφοριακές τεχνολογίες συγκέντρωσης κι ανάλυσης δεδομένων σε μαζική κλίμακα.
Την επόμενη χρονιά, ήταν η ίδια η Microsoft πλέον που ήρθε να μιλήσει πιο “σοβαρά” για το θέμα, βάζοντας τη βούλα της κι ονοματίζοντας τη διαδικασία μετάβασης προς ένα νέο επιστημονικό παράδειγμα, εκδίδοντας ένα βιβλίο με τον τίτλο The Fourth Paradigm: Data-Intensive Scientific Discovery (Το Τέταρτο Παράδειγμα: Επιστημονική Ανακάλυψη Έντασης Δεδομένων). Το τέταρτο παράδειγμα προφανώς αναφέρεται στο σήμερα. Σύμφωνα με το βιβλίο, η επιστήμη έχει περάσει ήδη από τρία προηγούμενα παραδείγματα: ένα προ-Αναγεννησιακό που ήταν κατά βάση εμπειρικό κι απλώς περιέγραφε τα φυσικά φαινόμενα· ένα δεύτερο, τους τελευταίους αιώνες, που εξηγούσε τα φαινόμενα με βάση θεωρητικές, μαθηματικές γενικεύσεις και τέλος ένα τρίτο, από τον Β παγκόσμιο κι έπειτα, που χρησιμοποιούσε αλγοριθμικά μοντέλα προσομοίωσης των φυσικών φαινομένων. Στο σημερινό τέταρτο παράδειγμα το κέντρο βάρους (υποτίθεται ότι) πέφτει σε εκείνο το σημείο της επιστημονικής διαδικασίας που βρίσκεται πριν την κατάστρωση θεωρητικών μοντέλων και την κωδικοποίησή τους σε αλγορίθμους: στα ίδια τα δεδομένα και στη συλλογή τους σε μαζική κλίμακα και μόνο κατόπιν στην εξαγωγή θεωρητικών μοντέλων, τα οποία ούτως ή άλλως θα μπορούν να παράγονται κι αυτόματα από «έξυπνους» αλγορίθμους, βρίσκοντας τα κατάλληλα μοτίβα που υπάρχουν κρυμμένα μέσα στους σωρούς των πρωτογενών δεδομένων. Κι εφόσον έτσι (θα) δουλεύει η επιστήμη, θα πρέπει και οι πρακτικές μέσα στο εργαστήριο να συμμορφωθούν με αυτό το μοντέλο: μεγάλες κι ανοιχτές βάσεις δεδομένων, σχεδιασμένες στη βάση αυστηρών προτύπων για ευκολότερο διαμοιρασμό, αποδοτικά και κατά το δυνατόν αυτοματοποιημένα εργαλεία λογισμικού για την ανεύρεση κι εξόρυξη μοτίβων, εργαλεία λογισμικού που θα διαχειρίζονται ολόκληρη τη ροή εργασίας, από τη συλλογή των δεδομένων μέχρι την αποθήκευση, ανάλυση και παρουσίασή τους· ακόμα κι αλλαγές στο υπάρχον σύστημα επιστημονικών δημοσιεύσεων ώστε να μπορούν εύκολα να αναπαράγονται τα αποτελέσματα των διαφόρων άρθρων αλλά και να συνδέονται τα άρθρα τόσο μεταξύ τους όσο και με ψηφιακά δεδομένα (εδώ έχουν να κλάψουν κάποιοι εκδοτικοί οίκοι, αλλά κυρίως ακαδημαϊκοί που καταφέρνουν να αβγατίζουν δημοσιεύσεις με το να παρουσιάζουν τα ίδια και τα ίδια, ελαφρώς παραλλαγμένα και σχεδόν αδύνατο να αναπαραχθούν από οποιονδήποτε άλλο).
Τα παραπάνω είναι πιο πιθανό να τα έχετε πετύχει υπό τον πιο πιασάρικο όρο “Big Data”, ο οποίος έχει κάπως ευρύτερο νόημα - εφόσον μπορεί να αναφέρεται και σε δεδομένα που δεν έχουν απαραίτητα σχέση με την επιστήμη - και που τείνει να “αποκρύπτει” το γεγονός ότι δεν πρόκειται απλώς για μεγάλα κι ετερογενή δεδομένα, αλλά ακριβώς για μια απόπειρα επανανοηματοδότησης του σε τι συνίσταται εν τέλει η χρησιμότητα των δεδομένων και του πώς (πρέπει να) εξάγονται συμπεράσματα από αυτά.
πόσο “δεδομένα” είναι τελικά τα δεδομένα;
Αυτά έχουν να μας πουν όσοι “οραματιστές” από την επιστημονική ελίτ βρίσκονται στην αιχμή των τεχνολογικών εξελίξεων. Το να παίρνει βέβαια κανείς τοις μετρητοίς τον τρόπο που οι ίδιοι οι μηχανικοί και οι επιστήμονες κατανοούν και παρουσιάζουν τον εαυτό τους είναι ο πιο ασφαλής δρόμος για να μην κατανοήσει τίποτα από τις δυναμικές που ωθούν τις όποιες εξελίξεις. Ας ξεκινήσουμε από τα πολύ βασικά, με μερικές παρατηρήσεις σε σχέση με την χρησιμοποιούμενη ορολογία. Είναι τα Big Data ένα νέο παράδειγμα; Είναι καν παράδειγμα, με την επιστημολογική, κουνιανή έννοια του όρου; Αν ξεφυλλίσει κανείς το Τέταρτο Παράδειγμα, θα δυσκολευτεί να βρει έστω και λίγες αναφορές στους λεγόμενους εξω-επιστημονικούς παράγοντες διαμόρφωσης του “νέου παραδείγματος”. Για την ακρίβεια, η παντελής έλλειψη αναφοράς σε ο,τιδήποτε φαίνεται να κουβαλάει τη “βρωμιά” του κονωνικο-πολιτικού παράγει μια περιγραφή της εξέλιξης από το πρώτο, προ-Αναγεννησιακό Παράδειγμα μέχρι το σημερινό ως εάν η εξέλιξη αυτή να ήταν μια εσωτερική κι αυτοτελής κίνηση του επιστημονικού πνεύματος κατά την αναζήτηση της Γνώσης. Εδώ λοιπόν δεν έχουμε να κάνουμε με μια μικρή αστοχία κι απρόσεκτη χρήση του όρου “παράδειγμα”, αλλά με την πλήρη νοηματική αντιστροφή αυτού που προσπάθησε να περιγράψει ο Κουν. Κάτι λέγαμε στην αρχή περί κατάχρησης του όρου. Ιδού ένα τρανταχτό παράδειγμα...
Μικρό το κακό, θα έλεγε κανείς. Το γεγονός ότι οι επιστήμονες αδυνατούν να κατανοήσουν και να χρησιμοποιήσουν όρους εκτός του πεδίου τους (ω, τι έκπληξη, αλήθεια!) δεν συνεπάγεται και την πραγματική απουσία μιας αλλαγής παραδείγματος που μπορεί να τρέχει αυτή τη στιγμή. Θα επανέλθουμε και παρακάτω σε αυτό το θέμα. Για την ώρα, θα αρκεστούμε σε μια ακόμα ορολογική επισήμανση. Αν υποθέσουμε (υπόθεση που είναι βάσιμη) ότι όντως παρατηρείται μια στροφή προς τη μαζική συλλογή δεδομένων και την αλγοριθμική ανάλυσή τους, τότε ποια είναι η σχέση αυτής της νέας κατεύθυνσης με τα αμέσως προηγούμενα επιστημονικά μοντέλα σκέψης και πρακτικής, αυτά που υποτίθεται ότι ανατρέπει; Ένα βασικό συστατικό των αλλαγών παραδείγματος (ξαναλέμε, όπως τις περιέγραψε ο Κουν) είναι και η αδυναμία “αντικειμενικής” σύγκρισης ανάμεσα στο παλιό και στο νέο παράδειγμα· με άλλα λόγια μια ασυμμετρία που φαίνεται να υπάρχει μεταξύ τους, ακόμα και σε επίπεδο ερμηνείας βασικών εννοιών, τέτοια ώστε και η απλή συνεννόηση μεταξύ των οπαδών του κάθε παραδείγματος να γίνεται προβληματική. Κάθε παράδειγμα ζει μέσα στον εαυτό του, αποτελώντας μια συνολική κοσμοθεώρηση (με τις αντίστοιχες οντολογικές προεκτάσεις), με τις δικές της έννοιες, τις δικές της προτεραιότητες κι εν τέλει με τις δικές της αξίες. Είναι μάλλον προφανές ότι η όποια στροφή προς τη μαζική χρήση δεδομένων δεν αποτελεί σε καμμία περίπτωση τομή τέτοιου βάθους σε σχέση με την προηγούμενη αλγοριθμική φάση της επιστήμης ώστε να χρειάζεται ο όρος παράδειγμα για να περιγραφεί. Επί της ουσίας, πρόκειται για το ίδιο εννοιακό οπλοστάσιο, μόνο που αυτή τη φορά στοχεύει προς... ο,τιδήποτε κινείται και μάλιστα σε πραγματικό χρόνο. Αν πρέπει να χρησιμοποιηθεί ο όρος παράδειγμα, με την επιστημολογική του έννοια, τότε η ημερομηνία γέννησης του σημερινού εντοπίζεται αρκετά πιο πίσω, τουλάχιστον έναν αιώνα, κατά την κρίση των μαθηματικών στις αρχές του 20ου.
Ανεξάρτητα από την όποια “σχολαστική” συζήτηση γύρω από την έννοια του Παραδείγματος, τα Big Data, έστω ως μια νέα μεθοδολογία (και πρωτίστως ως νέο “πρόβλημα προς επίλυση”), φαίνεται ότι ήρθαν για να μείνουν. Κι ο ενθουσιασμός (μαζί με χρήματα κι ερευνητικά προγράμματα) δεν λείπει. Θα κάνουμε προς στιγμή τα στραβά μάτια, παριστάνοντας ότι δεν βλέπουμε τον χορό των κονδυλίων, των συνεδρίων και των ακαδημαϊκών θέσεων που στήνεται γύρω τους. Από καθαρά επιστημολογική άποψη λοιπόν, το πλεονέκτημα των Big Data σε σχέση με τις προηγούμενες επιστημονικές μεθόδους (υποτίθεται ότι) είναι... η ακρίβεια και η αντικειμενικότητα (τι άλλο!). Και γιατί άραγε; Υπάρχει μια απλοϊκή λογική που μπορεί με ευχέρεια να μεταφράζει ποσοτικά μεγέθη σε ποιοτικά κριτήρια και σίγουρα έχει βάλει κι αυτή το χέρι της εδώ. Περισσότερα δεδομένα σημαίνουν πληρέστερη κάλυψη του πεδίου που μελετάται και πιο ενδελεχής εξέταση όλων των πιθανών εξηγήσεων για ένα φαινόμενο. Όμως δεν είναι μόνο τα ίδια τα δεδομένα και το μέγεθός τους που παίζουν ρόλο. Αν ο όγκος των δεδομένων επιβάλλει τη χρήση αλγορίθμων για τον χειρισμό τους, τότε οι αλγόριθμοι αυτοί (και πάλι υποτίθεται ότι) θα μπορούν να “εκπαιδευτούν” ώστε να βρίσκουν μόνοι τους συσχετίσεις ή κι ακόμα να παράγουν οι ίδιοι τα βέλτιστα θεωρητικά μοντέλα που θα ταιριάζουν καλύτερα με τα δεδομένα. Εξοβελίζοντας τις προ-κατασκευασμένες θεωρίες, απαλλασσόμαστε κι από το βάρος της ανθρώπινης υποκειμενικότητας που αυτές εξ ορισμού φέρουν, άρα παράγουμε τελικά πιο αντικειμενικές θεωρίες.
Λογικοφανή τα παραπάνω. Μόνο που η ευλογοφάνεια είναι ο εχθρός της κριτικής. Το γεγονός ότι δεν υπάρχουν “ωμά”, “ακατέργαστα” κι “αντικειμενικά” δεδομένα είναι μια πρώτη ένσταση εδώ. Ακόμα και τα απλούστερα δεδομένα που μπορεί να λαμβάνονται κατευθείαν από αισθητήρες προϋποθέτουν ήδη ότι “κάποιος” έχει κάνει μια συγκεκριμένη επιλογή σχετικά με το ποια από αυτά πρέπει να ληφθούν και πώς πρέπει να μετρηθούν. Πόσο “αντικειμενικό” είναι να μετράται η ισχύς ενός φιλικού δεσμού μέσα από τα like του facebook ή το ηλεκτρικό φορτίο ενός σωματιδίου μέσα από την αλληλεπίδρασή του με το τάδε ή το δείνα υλικό ενός επιταχυντή; Εξαρτάται! Καταρχήν, από το αν το παράδειγμα (δηλαδή η θεωρία) λέει ότι το φορτίο ή τα like είναι κάτι που αξίζει να μετρηθούν. Με πιο φιλοσοφικούς-επιστημολογικούς όρους, πρόκειται για αυτό που έχει ονομαστεί ως η θεωρητική φόρτιση κάθε πειραματικής παρατήρησης και δεν είναι καν κάποιο καινούριο εύρημα. Αλλά για τους θιασώτες των Big Data, αυτά είναι ψιλά γράμματα, αν και φυσικά εννοείται ότι οι πιο υποψιασμένοι γνωρίζουν ότι δεδομένα χωρίς θεωρία απλώς δεν είναι δυνατό να υπάρξουν. [4Το επιχείρημα περί θεωρητικής φόρτισης δεν είναι άγνωστο (έστω με άλλους όρους) σε όσους επιστήμονες ασχολούνται με “έξυπνους” αλγορίθμους μηχανικής μάθησης, δηλαδή με αλγορίθμους που εξάγουν συμπεράσματα-θεωρίες μέσα από δεδομένα. Ο σκοπός ενός τέτοιου αλγορίθμου είναι πρώτα να εκπαιδευτεί με κάποια αρχικά δεδομένα και μετά να μπορεί να βγάζει τα “σωστά” συμπεράσματα αξιοποιώντας και καινούρια δεδομένα. Π.χ., αν ένας αλγόριθμος έχει μάθει να αναγνωρίζει γάτες, “βλέποντας” κάποιες αρχικές φωτογραφίες, θα πρέπει να μπορεί να τις αναγνωρίζει και σε φωτογραφίες που δεν έχει “ξαναδεί”. Κι εδώ έρχεται το ενδιαφέρον. Όλοι αυτοί οι αλγόριθμοι πάντα ξεκινάνε με κάποιου είδους “προκατάληψη” (bias) ως προς το ποιες θεωρίες (π.χ. κανόνες για αναγνώριση γατιών) θα μάθουν ή, για να είμαστε πιο ακριβείς, ποιες κλάσεις θεωριών θα μπορούν να μάθουν. Κι όχι μόνο αυτό, αλλά είναι γνωστό ότι ένας τελείως απροκατάληπτος αλγόριθμος το μόνο που θα κατάφερνε να μάθει θα ήταν οι γάτες των αρχικών φωτογραφιών και τίποτα άλλο. Σε οποιαδήποτε νέα φωτογραφία που δεν είχε ξαναδεί, θα πάθαινε... εγκεφαλικό, βγάζοντας άλλα αντ' άλλων.]
Μια δεύτερη ένσταση δεν είναι τόσο προφανής κι έχει να κάνει με το γεγονός ότι χρήση μαζικών δεδομένων ενδέχεται όχι μόνο να μην βελτιώνει την αντικειμενικότητα, αλλά να λειτουργεί κι εντελώς αντίστροφα! Όταν μιλάμε για τόσο τεράστιους όγκους δεδομένων, η εύρεση κανονικοτήτων και συσχετίσεων μπορεί να μην είναι καθόλου σπάνια υπόθεση κι έτσι το πρόβλημα θα μετατεθεί στο ποια απ' όλες τις ανευρεθείσες συσχετίσεις είναι πιο “πραγματική” από τις άλλες. Με λίγο πείραγμα των παραμέτρων, υποθέτουμε ότι ο καθένας θα μπορεί να βρει ό,τι ακριβώς ψάχνει. Υπάρχει μάλιστα κι ένα “ανέκδοτο” που κυκλοφορεί στη σχετική βιβλιογραφία, που αφορά το γεγονός ότι “αποδείχτηκε”, με χρήση μαζικών δεδομένων, ότι ένας αμερικανικός χρηματιστηριακός δείκτης εμφάνιζε έντονη συσχέτιση με την παραγωγή βουτύρου στο Μπαγκλαντές. Συμπέρασμα; Με μια απεργία στο Μπαγκλαντές, θα καταρρεύσει το αμερικανικό χρηματιστήριο. Ζήτω η θεωρία του χάους!
Και πέρα από το στάδιο της ανάλυσής τους όμως, τα μαζικά δεδομένα είναι επιρρεπή ως προς την “εισβολή” της υποκειμενικότητας ακόμα και κατά τη συλλογή τους· και μάλιστα τόσο πιο επιρρεπή όσο πιο μαζικά είναι. Ο λόγος; Αντιπροσωπευτική δειγματοληψία τον λένε (τα “Big Data” των εκλογικών δημοσκοπήσεων τα θυμάστε;), που γίνεται όλο και πιο προβληματική όσο μεγαλύτερο το εύρος που πρέπει να καλυφθεί και που είναι απλώς ανύπαρκτη όταν πρόκειται για “αδέσποτα” και “τυχαία” δεδομένα, όπως οι δημοσιεύσεις σε κοινωνικά δίκτυα.
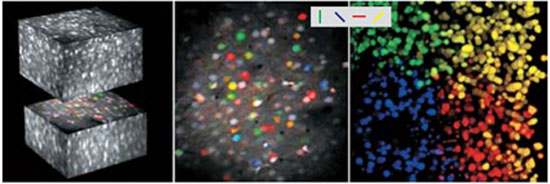
Τρισδιάσταση ανακατασκευή χιλίων νευρώνων (αριστερά) από τον εγκέφαλο ποντικού, «ενώνοντας» υπολογιστικά πολλές μεμονωμένες εικόνες-φέτες (μέσο). Και πάλι, αποτέλεσμα αλγοριθμικής διαχείρισης τεράστιων όγκων από δεδομένα.
η εξαφάνιση της θεωρίας (ή το θέαμα ως θεωρία)
Σε κάθε περίπτωση, σκοπός μας δεν είναι να γελοιοποιήσουμε τους ισχυρισμούς όσων βρίσκουν στα Big Data κάποιο νέο υπέρ-παράδειγμα· ισχυρισμοί που ούτως ή άλλως έχουν έντονο το προπαγανδιστικό στοιχείο. Οι όποιες πραγματικές αλλαγές μπορεί να συνοδεύουν ένα νέο μοντέλο επιστημονικής σκέψης και πρακτικής, ακόμα κι αν αυτό δεν συνιστά Παράδειγμα με την αυστηρή σημασία του όρου, έχουν μεγαλύτερο ενδιαφέρον. Μόνο που συχνά, για να μιλήσει κανείς για κάτι, πρέπει πρώτα να μιλήσει για το τι δεν είναι αυτό το κάτι. Έστω, λοιπόν, ότι δεν έχουμε να κάνουμε με κάποιο Παράδειγμα· κι έστω ότι τα Big Data δεν είναι το δισκοπότηρο της αντικειμενικότητας κι ούτε θα μας απαλλάξουν από τις άβολα υποκειμενικές θεωρίες. Αυτό σημαίνει ότι όσοι φυσικοί μάθανε να δουλεύουν με τον κλασσικό τρόπο, καταστρώνοντας διαφορικές εξισώσεις (και περνώντας τες σε κάποιο πρόγραμμα προσομοίωσης), μπορούν να κοιμούνται ήσυχοι; Δεν είμαστε τόσο σίγουροι για αυτό.
Ακόμα κι αν δεν εξαφανιστεί η ανάγκη για θεωρητικά μοντέλα στην επιστήμη, δεν είναι καθόλου απίθανο η εισαγωγή επί της ουσίας ταιηλορικών αρχών διαχείρισης δεδομένων να συνεπιφέρει μια περισσότερο πολυεπίπεδη διαστρωμάτωση του επιστημονικού δυναμικού. Με πιο “κυνικούς” και πραγματιστικούς όρους, μια αναδιάρθρωση του καταμερισμού εργασίας μέσα στις τάξεις των επιστημόνων, όπου οι μάζες θα διαχειρίζονται δεδομένα χρησιμοποιώντας λίγο - πολύ προτυποποιημένα πακέτα έξυπνου λογισμικού και μια ελίτ “προνομιούχων” κατασκευαστών θεωριών, που ίσως ούτε κι αυτοί να μην έχουν συνολική εποπτεία ολόκληρου του πεδίου τους. Όπως επίσης δεν είναι απίθανο ένας τέτοιος καταμερισμός να έχει με τη σειρά του κι επιστημολογικές συνέπειες. Από τη στιγμή που η θεωρία μετατίθεται, εγγράφεται και κωδικοποιείται στα αρχικά στάδια μιας μακράς αλυσίδας επεξεργασίας δεδομένων, δεν θα είναι κι εύκολο (ή κι επιτρεπτό) να εμφανίζει ρωγμές που θα απειλούν με κατάρρευση όλη την αλυσίδα. Κάτι που βέβαια δεν αποκλείει (και που η φύση του λογισμικού μάλλον πριμοδοτεί) την περίπτωση συχνής εμφάνισης ανταγωνιζόμενων θεωριών, που θα δημιουργούν τα δικά τους παράλληλα και συμπαγή εννοιακά “οικοσυστήματα”, το καθένα με κυμαινόμενους βαθμούς επιτυχίας και διάρκεια ζωής.
Παραμένοντας τώρα στο επίπεδο του επιστήμονα - μάζα, πώς θα μπορούσε να γίνει κατανοητή η δραστηριότητα ενός τέτοιου εργάτη του (επιστημονικού) πνεύματος, που θα επιδίδεται στο κυνήγι της ταχείας ανεύρεσης συσχετίσεων, ενδεχομένως αδιαφορώντας για τους αφανείς μηχανισμούς που παρήγαγαν τις συσχετίσεις; Μια διευκρίνιση πρώτα. Θα μπορούσε να υποστηρίξει κανείς ότι η ταχεία ανεύρεση συσχετίσεων (η έμφαση στο “ταχεία” εδώ) δεν είναι καν ζητούμενο της επιστημονικής έρευνας και ούτως ή άλλως στα μεγάλα επιστημονικά προγράμματα θεωρείται αυτονόητο ότι η ανάλυση των δεδομένων χρειάζεται κάποιο σεβαστό χρόνο για να δώσει αποτελέσματα. Σωστό αυτό και θα συμπληρώναμε ότι η απαίτηση για ταχύτητα προέρχεται κυρίως από εμπορικά συστήματα ανάλυσης μεγάλων δεδομένων που εστιάζουν κυρίως στην πρόβλεψη τάσεων, εκεί όπου μια απόκλιση της τάξης λίγων κλασμάτων του δευτερολέπτου μπορεί να κάνει τη διαφορά. Χαρακτηριστικό παράδειγμα οι αλγόριθμοι που τρέχουν πάνω σε χρηματιστηριακά δεδομένα ή οι αλγόριθμοι “δημοπρασίας” διαδικτυακών διαφημίσεων. Σωστό, αλλά... αυτό δεν συνεπάγεται ότι τέτοια “ταπεινά” κίνητρα κέρδους, μαζί με τις αντίστοιχες τεχνικές που τα τροφοδοτούν, δεν μπορούν να ρίξουν τη σκιά τους πάνω στο “καθαρό” επιστημονικό πνεύμα. Μόνο η αφέλεια και η ιστορική άγνοια μπορούν να δικαιολογήσουν την αντίληψη που θέλει το “υψηλό” πνεύμα της επιστήμης να κινείται σε μια αμόλυντη σφαίρα των ιδεών, ανεπηρέαστο από τα πολύ ταπεινά και καθημερινά της κοινωνικής ζωής. Τα παραδείγματα επιστημονικών ιδεών που είχαν πολύ ταπεινή καταγωγή δεν είναι και λίγα.
Κι ερχόμαστε στο ζήτημα της (ηθελημένης ή επιβεβλημένης λόγω καταμερισμού) “αδιαφορίας” για τους μηχανισμούς παραγωγής των συσχετίσεων. Η φιλοσοφία και η κοινωνιολογία της επιστήμης, μέσα στην εξέλιξή τους και λόγω κάποιων πιο “αιρετικών” θεωριών που αμφισβητούσαν αφελείς αντιλήψεις περί της επιστήμης σαν πιστής αναπαράστασης της πραγματικότητας, αναγκάστηκαν να δημιουργήσουν σε κάποιες βασικές διακρίσεις όσον αφορά στο νόημα της εξήγησης ενός φυσικού φαινομένου. [5Για να είμαστε δίκαιοι, τέτοιοι προβληματισμοί σχετικά με την εξήγηση των φαινομένων (τον ρόλο των αισθήσεων και της αξιοπιστίας τους, τις πολλαπλές ερμηνείες τους, κ.τ.λ.) δεν υπήρξαν το αποκλειστικό προνόμιο της φιλοσοφίας και της κοινωνιολογίας της επιστήμης, όπως αυτές διαμορφώθηκαν τις τελευταίες δεκαετίες. Αν κανείς θέλει να το πάει πολύ πίσω, θα μπορούσε να φτάσει μέχρι τους αρχαίους σοφιστές και σκεπτικούς.] Μια τέτοια βασική διάκριση είναι εκείνη ανάμεσα στο παρατηρούμενο φαινόμενο αυτό καθεαυτό, στην αναπαράστασή του υπό τη μορφή συγκεκριμένων μετρήσεων και τελικά στην ερμηνεία του υπό τη μορφή θεωριών. Αντιλαμβάνεται κανείς ότι για να έχει γίνει μια τέτοια διάκριση, οι σχέσεις ανάμεσα στους τρεις πόλους του τριγώνου φαινόμενο - αναπαράσταση - θεωρία δεν είναι καθόλου προφανείς. Ποιος μετράει τι, υπό ποιους όρους, πώς ερμηνεύονται οι μετρήσεις, πόσες συνεκτικές θεωρίες μπορούν να ερμηνεύουν το φαινόμενο· αυτά είναι μόνο μερικά από τα ζητήματα που έχουν ανοιχτεί, χωρίς εύκολες απαντήσεις. Το δόγμα που λέει “μια συσχέτιση μού είναι αρκετή και δεν μ' ενδιαφέρουν οι θεωρίες”, πέρα από το πρόβλημα εύρεσης της πιο “πραγματικής” από τις συσχετίσεις που αναφέρθηκε παραπάνω, συνιστά και μια κίνηση απορρόφησης τόσο του φαινομένου όσο και της θεωρίας μέσα στην αναπαράσταση της στατιστικής συσχέτισης, τουλάχιστον για όσους (θα) δουλεύουν σε αυτό το επίπεδο. Κι αν αυτό συνδυαστεί με την τάση που δείχνουν τα μεγάλα επιστημονικά προγράμματα, σαν αυτά που θέλει να χειριστεί η μεθοδολογία των Big Data, να συγκροτούνται σαν μακρές αλυσίδες τόσο υλικών όσο και “άυλων” (βλέπε λογισμικό) συσκευών, με εκατοντάδες επιστήμονες να δουλεύουν σε διαφορετικά τμήματα της αλυσίδας, τότε και η μυστικοποίηση των εξεταζόμενων φαινομένων είναι μόλις ένα βήμα μακριά. Μάλλον δεν είναι τυχαίο αυτό που παρατηρείται ήδη σε πειράματα σαν αυτά στο CERN - που λειτουργούν ακριβώς με μια τέτοια λογική - με τους συμμετέχοντες επιστήμονες να εκφράζονται σε μια γλώσσα που έχει ομοιότητες με αυτή της αποφατικής θεολογίας! [6Για αυτό το θέμα, βλ. το μάλλον άχαρο κι ανερμάτιστο, αλλά σχετικά χρήσιμο βιβλίο της Knorr-Cetina, Epistemic cultures: how the sciences make knowledge.] Μια υπολογιστικά ανακατασκευασμένη τροχιά του μποζονίου Higgs ως μυστικοποιημένη αναπαράσταση: είπε κανείς ότι το θέαμα δεν έχει καμμία δουλειά στα χωράφια της επιστήμης;
Μιλώντας με τους όρους της ανάγνωσης του Μαρξ απ’ την ιταλική εργατική αυτονομία, η τοποθέτηση της μηχανής (ανάλυσης των Big Data) στο επίκεντρο της επιστημονικής πρακτικής ως το καθολικό και κυρίαρχο μέσο διαμεσολάβησης της επιστημονικής σκέψης θα μπορούσε να κωδικοποιηθεί στη φράση πραγματική υπαγωγή της επιστήμης στο κεφάλαιο. Η τυπική της υπαγωγή είναι δυνατό να εντοπιστεί, αν όχι νωρίτερα, τότε σίγουρα ήδη από τον 19ο αιώνα, όταν τον έλεγχο και την εξωτερική οργάνωσή της αναλαμβάνουν κατά κύριο λόγο το κράτος, μέσω των πανεπιστημίων, και οι επιχειρήσεις, μέσω των εργαστηρίων τους. Η εσωτερική αναδιάρθρωσή της που επιχειρείται τώρα, στη βάση οικονομικών (εντός κι εκτός εισαγωγικών) κριτηρίων απόδοσης της μηχανής και κοινωνικών κριτηρίων θεάματος αποτελεί κι ένα στάδιο καπιταλιστικής ωρίμανσής της. Από αυτή την άποψη λοιπόν, το τέταρτο παράδειγμα δεν συνιστά κάποια αρχή (μιας νέας επιστημονικής περιόδου), αλλά μάλλον την ολοκλήρωση κι οργανική ενσωμάτωση εντός του καπιταλιστικού κύκλου αυτού που υπήρξε κάποτε το καμάρι του κλασσικού, αστικού φιλελευθερισμού: του ανεξάρτητου επιστημονικού πνεύματος. Ακριβώς το μοντέλο επιστήμης που “κλειδώνει” βέλτιστα στις προσταγές ενός μεταμοντέρνου, θεαματικού κόσμου, δίχως μεγάλες αφηγήσεις...
Δεν είμαστε από αυτούς που θα θρηνήσουν και θα χύσουν δάκρυα για την αίγλη του παραδοσιακού επιστημονικού πνεύματος που διαλύεται μπροστά στην επέλαση της μηχανής. Τέτοια δάκρυα τα αφήνουμε για τους εργολάβους του ορθόδοξου “μαρξισμού” - που ακόμα δυσκολεύονται να χωνέψουν το πόσο στενά συγγενεύουν με τον αστικό φιλελευθερισμό. Ούτε έχουμε τη διάθεση να υποτιμήσουμε το νέο μοντέλο, από την άποψη της επιστημολογικής του αξίας. Όσοι σπεύσουν να προδικάσουν τη φτώχεια του ως προς την παραγωγή συναρπαστικών θεωριών, ίσως θα ήταν φρόνιμο να ρίξουν πρώτα μια ματιά στις παρόμοιες ενστάσεις που είχαν ορισμένοι μαθηματικοί κατά τις αρχές του 20ου αιώνα, όταν άρχισε να εμφανίζεται το αλγοριθμικό Παράδειγμα στα μαθηματικά (αν κι αυτό ήταν όντως Παράδειγμα, με την κουνιανή έννοια). Αυτό που σίγουρα μας ενδιαφέρει πάντως είναι η δική μας υποτίμηση, μέσω της μετατροπής μας σε παραγωγικά και καταναλωτικά εξαρτήματα, στα άκρα μιας αδιαφανούς και μυστικοποιημένης μηχανικής αλυσίδας. Και δεν μας περισσεύει κάποια χείρα συμπόνιας για να εκτείνουμε προς τον επιστήμονα-μάζα, όσο αυτός επιμένει να ακούει τον αποχαυνωτικό βόμβο της. Την χαύνωσή του εμείς την πληρώνουμε ακόμα πιο ακριβά.
Separatrix
Σημειώσεις
1 - Για ένα πιο χειροπιαστό παράδειγμα κακοποίησης εννοιών, μπορεί κανείς να δει το τι έχει τραβήξει η λέξη “επανάσταση” στα χέρια των διαφημιστών. Για να μην μιλήσουμε για τους “πολιτικούς ειδικούς” του είδους, που στα μέρη μας τους συναντάει κανείς σε κάθε γωνία.
[ επιστροφή ]
2 - Το έργο του Κουν θεωρείται ορόσημο κυρίως στον αγγλοσαξωνικό κόσμο. Η ηπειρωτική Ευρώπη (κυρίως η Γαλλία) είχε να επιδείξει παρόμοιο έργο (αν και λιγότερο γνωστό, για προφανείς λόγους) ήδη πριν τον Κουν. Βλ. το βιβλίο του Dominique Lecourt, Marxism and Epistemology: Bachelard, Canguilhem and Foucault.
[ επιστροφή ]
3 - Βλ. σχετικό άρθρο στο τεύχος 4 του Cyborg, Περί αλλαγής παραδείγματος
[ επιστροφή ]
4 - Το επιχείρημα περί θεωρητικής φόρτισης δεν είναι άγνωστο (έστω με άλλους όρους) σε όσους επιστήμονες ασχολούνται με “έξυπνους” αλγορίθμους μηχανικής μάθησης, δηλαδή με αλγορίθμους που εξάγουν συμπεράσματα-θεωρίες μέσα από δεδομένα. Ο σκοπός ενός τέτοιου αλγορίθμου είναι πρώτα να εκπαιδευτεί με κάποια αρχικά δεδομένα και μετά να μπορεί να βγάζει τα “σωστά” συμπεράσματα αξιοποιώντας και καινούρια δεδομένα. Π.χ., αν ένας αλγόριθμος έχει μάθει να αναγνωρίζει γάτες, “βλέποντας” κάποιες αρχικές φωτογραφίες, θα πρέπει να μπορεί να τις αναγνωρίζει και σε φωτογραφίες που δεν έχει “ξαναδεί”. Κι εδώ έρχεται το ενδιαφέρον. Όλοι αυτοί οι αλγόριθμοι πάντα ξεκινάνε με κάποιου είδους “προκατάληψη” (bias) ως προς το ποιες θεωρίες (π.χ. κανόνες για αναγνώριση γατιών) θα μάθουν ή, για να είμαστε πιο ακριβείς, ποιες κλάσεις θεωριών θα μπορούν να μάθουν. Κι όχι μόνο αυτό, αλλά είναι γνωστό ότι ένας τελείως απροκατάληπτος αλγόριθμος το μόνο που θα κατάφερνε να μάθει θα ήταν οι γάτες των αρχικών φωτογραφιών και τίποτα άλλο. Σε οποιαδήποτε νέα φωτογραφία που δεν είχε ξαναδεί, θα πάθαινε... εγκεφαλικό, βγάζοντας άλλα αντ' άλλων.
[ επιστροφή ]
5 - Για να είμαστε δίκαιοι, τέτοιοι προβληματισμοί σχετικά με την εξήγηση των φαινομένων (τον ρόλο των αισθήσεων και της αξιοπιστίας τους, τις πολλαπλές ερμηνείες τους, κ.τ.λ.) δεν υπήρξαν το αποκλειστικό προνόμιο της φιλοσοφίας και της κοινωνιολογίας της επιστήμης, όπως αυτές διαμορφώθηκαν τις τελευταίες δεκαετίες. Αν κανείς θέλει να το πάει πολύ πίσω, θα μπορούσε να φτάσει μέχρι τους αρχαίους σοφιστές και σκεπτικούς.
[ επιστροφή ]
6 - Για αυτό το θέμα, βλ. το μάλλον άχαρο κι ανερμάτιστο, αλλά σχετικά χρήσιμο βιβλίο της Knorr-Cetina, Epistemic cultures: how the sciences make knowledge.
[ επιστροφή ]